It helps to divide code into easy to understand units. Layering is a tool in the code quality tool belt to help with this. Essentially you drive wedges between the pieces of a larger problem space. These small problems are layers. Each layer has a unique characteristic and sits in an ordered list by that characteristic.
For example, in computer networking layers are employed readily in protocol stacks. The Internet protocol suite (commonly IP/TCP) is illustrated with layers:

At the top, we are furthest removed from the hardware and extending down we get closer and closer to the raw metal. Each layer provides functionality which the lower layers to not provide which is useful to the layers above it.
Layering as a problem modeling technique is broadly applicable. For code quality, layering aims to help with:
- Organizing larger problems in a logical way
- Encapsulating concerns such that they are only dealt with uniquely in a few places
- Enabling good reuse of functionality (as opposed to simply focusing on de-duplication of code as text)
- Applying friction to make bad code harder to write
Approaches
A common way to layer code is by its applicability. In this way layers help answer the question, 'When does it makes sense to (re)use this code for the problem we are solving?' Exploring this in a business setting we may define layers like this:
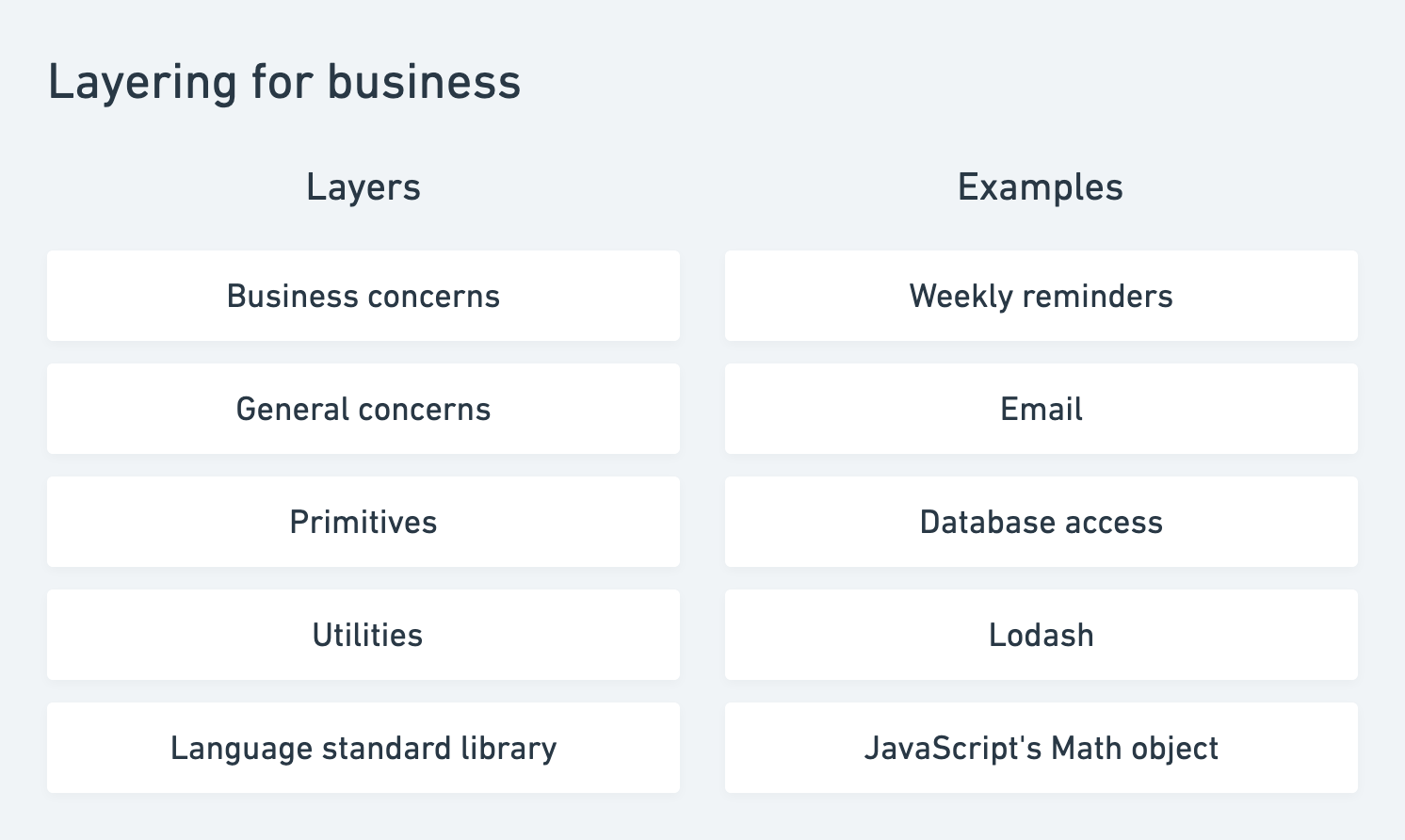
Breaking these layers down from bottom to top:
-
Language standard library code provides the very basics of working in whatever programming language you choose. Some languages provide more comprehensive libraries than others. JavaScript for example doesn't have a strong standard library. (It has been getting better over time.) The features the language provides are ever present and generally applicable to solving problems.
In terms of mental overhead, it is common to imply everyone working in a language is familiar with the standard library. On the flip side, don't use all of a language's standard library just for the sake of it. Standard libraries can be bad, deprecated, broken, obscure code too, for example JavaScript's
Dateobject. -
Utilities cover the short-comings of the standard library and paper over the ever present language problems with better features. For example, Lodash is a common open-source "utility belt" to compensate for JavaScript's lacking set. Utilities need not be open-source, but it's a good rule of thumb that if you weren't comfortable open sourcing the code, it probably isn't a utility.
Most often the set of utilities you have will be small because there are few constructs one can write that are both very generic and generally applicable.
-
Primitives are where we start building themes of code, things most programs need to deal with to be useful programs. This includes storage (database access or access to file systems), networking, compute management (process or thread management), secrets, logging, and monitoring. Conceivably anything you would build may rely on these primitive pieces to meet its requirements.
Note that these themes can be quite complex, unlike utilities which definitely ought to have guessable, simple internals and low complexity. Primitives juggle the problem of exposing just enough flexibility to use cases while maintaining good commonalities.
Primitives might be thought of as the "building blocks" of the code because they are composed together to solve most problems. They may be underpinned by full systems. For example managing the database servers could be encapsulated: you use the database access primitive and you get the management for free conceptually.
-
General concerns are answers to somewhat common problems. We can take email as an example; most code shouldn't shoulder the complexity of database storage, sending servers, etc. So we build on primitives and bundle up email as a concern.
These are less applicable than primitives and ought to be more prescriptive about how they are applied in both the code interface and documentation. Quite a many applications do not require email, for example.
-
Business concerns are where we actually do something useful. It can certainly be strange to say that because all the layers we've previous described are so complex, but it is true: thus far we've only built tools. This layer is where we apply them to specific problems. Things in this layer are least applicable to anything else.
If we built a feature of sending weekly reminders about how much money someone made, we would leverage:
- The email concern to send the emails out
- The data stored the database to pull completed transactions
-
The language's built-in
Array.reducemethod to sum up the totals
In this way, business concerns leverage the lower layers to make stuff happen.
The above layering is pretty common in larger organizations' engineering team structures and code bases, but with cooler names:
- Primitives → Infrastructure
- General concerns → Platform
- Business concerns → Product
Example: security
Multiple layering strategies can co-exist and fit within each other. To add one more example beside applicability, we can look at security. Specifically, let's talk about guarding against security vulnerabilities in the code that we write.

Breaking it down:
-
Raw, abusable features exist. They need to exist to enable all of the cool stuff we build. Some are better than others certainly insofar as making it most clear what is safe and isn't. The Document Object Model (DOM) allows low level access to web pages, loading scripts and other assets.
-
The trust boundary is the critical layer we use to encapsulate the above risk. It doesn't scale for each implementation built on top of the features above to carry the mental overhead or the risk. So the trust boundary restricts access to the lower interface and receives much more scrutiny, testing, and rigor.
For example, React wraps the DOM to safely encode HTML content by default. This solves issues with cross-site scripting (XSS) and content injection attacks.
<p>{'<script>evil()</script>'}</p> //=> <p><script>evil()</script></p> -
The use cases are the individual implementations. The goal is to have the code written at this layer impossible to screw up. Leveraging the trust boundary, the unsafe sharp edges aren't bleeding into everything else.
React does give an escape hatch
dangerouslySetInnerHTMLto work around this safety, but at least the risk is more obvious.<MyComponent dangerouslySetInnerHTML={{ __html: htmlString }} />
Evolution
It is fair to say most code is not written with layering in mind. As was touched on earlier, this is pretty understandable. When you are starting from scratch the layers may not be obvious in the beginning. If you are implementing weekly reminders but haven't built any other email feature, it may not be obvious there are parts to a full email service here.
Some good hints you might want to look into layering:
-
The Rule of Three basically says once you've written similar things three times start looking for commonalities. The weekly reminder email may be the only use case for awhile so introducing layering too early may frame solutions too closely to that exact shape of problem. By the time you also have welcome and password reset emails, you'll hopefully see a pattern forming to start building around.
-
Too much cognitive overhead to maintaining or adding new features. There are many ways to combat this, layering is one of them.
In our security example, if we found a vulnerability we needed to address we wouldn't need to scour all the code to patch it. We get it fixed at the trust boundary and every usage benefits with no or minimal work.
In our applicability example, ideally most work can be done in the mindset of one layer.
-
Spaghetti special casing of 'this or that' riddled throughout the code. For example, for customer A send this email otherwise do that other thing. These types of checks are very costly and layering can apply counter pressure and friction to these types of changes.
In our applicability example, lower level primitives and concerns would not have a concept of "customers." As such it would feel really bad and be quite brittle to hack up these lower layers to handle a business requirement. This would however be easier at the higher levels where the cost of getting it wrong is lower.
Similarly in our security example, if we riddled the trust boundary with special casing it would defeat a lot of the value of having the strict separation in the first place.
Knowing when applying layering makes sense and how to do so takes practice and good understanding of the situation. It's important to acknowledge layering for its own sake ought not be a goal, but for the benefits it should deliver. Layers are always a work in progress.